
-
Contents
- Exploring Solutions for Validating LLM Outputs
- Challenges of Manual Validation in LLM Context
- Diverse Applications Necessitating LLM Validation
- A Practical Approach Using OpenAI’s API
- The Integral Role of Validation in Enhancing LLM-Powered Systems

Exploring Solutions for Validating LLM Outputs
Large Language Models (LLMs), known for their capacity to generate a wide range of responses, often exhibit a level of unpredictability due to their inherent probabilistic nature. This variability stems from the models’ design to predict the likelihood of various words or sequences based on the data they have been trained on. Consequently, when given the same input, an LLM might produce different outputs on different occasions. This characteristic of LLMs poses a significant challenge in establishing a universal metric for assessing model efficiency. For each new task undertaken by an LLM, it becomes necessary to divide the evaluation process into multiple, task-specific metrics, each requiring its own unique method of assessment.
To address this challenge, several approaches have been developed for validating LLM performance:
- Utilizing Supervised Machine Learning Classifiers
One effective strategy involves the use of additional classifiers that are trained to identify specific attributes in the text generated by LLMs. For instance, a classifier designed to detect bias can flag potentially offensive content produced by an LLM. Running the outputs through these specialized ‘critic’ models can provide a valuable layer of validation.
- Benchmarking Against Specialized NLP Tasks
Another method involves scoring LLMs on specialized natural language processing benchmarks. These benchmarks typically have set answers for tasks such as reading comprehension or common sense reasoning, providing a standardized measure for evaluating the model’s performance in these specific areas.
- Incorporating Human Evaluations
Human assessment also plays a crucial role in the validation process. By having individuals review samples of text generated by LLMs, it is possible to gauge the coherence, factual accuracy, logical consistency, and alignment with intended goals of the content. Conducting these evaluations through panel studies can help to minimize the impact of individual biases.
These varied approaches to validation underscore the complexities involved in accurately assessing the performance of LLMs and highlight the need for multi-faceted validation strategies to ensure the reliability and appropriateness of their outputs.
Challenges of Manual Validation in LLM Context
The task of manually validating the outputs of Large Language Models (LLMs) presents formidable challenges. Given the expansive range of potential outputs that LLMs can generate from any given input, it becomes nearly impossible for human evaluators to manually review even a small fraction of these possibilities. The sheer volume of potential texts makes complete coverage through manual means an impractical endeavor.
Moreover, human involvement in the evaluation process introduces a degree of subjectivity and inconsistency. Attributes such as coherence or factual correctness in generated text are susceptible to subjective interpretation. Over time, human evaluators are prone to fatigue, which can lead to skewed standards or oversight. Maintaining consistent judgment across a wide array of outputs requires a level of effort and labor that is impractical in most scenarios.
Additionally, evaluating conversational LLMs poses its unique set of challenges. Unlike static text, assessing the quality and appropriateness of outputs from conversational models necessitates interactive testing. This involves engaging in prolonged dialogue episodes and navigating various scenarios, a task that rapidly becomes burdensome for human testers. The complexity of these interactions and the need for nuanced understanding of context and conversational flow further compound the difficulty of manual evaluation.
In summary, while manual validation of LLM outputs might seem straightforward, the reality is far more complex. The vast output range, coupled with inherent human biases and the intricate nature of conversational testing, makes manual validation a challenging and often impractical approach. As such, it underscores the necessity for automated, scalable, and objective validation methods in the realm of LLMs.
Diverse Applications Necessitating LLM Validation
The scope of validation for Large Language Models (LLMs) spans various applications, each with its unique requirements and challenges. This diversity underscores the versatility of LLMs and the importance of tailored validation approaches. Just to name a few applications, here’s our list:
- Customer Support Chatbot. This application demands rigorous validation to ensure the chatbot comprehends a wide range of user queries, maintains conversation context effectively, and provides relevant and accurate solutions.
- Social Media Moderation Bot. For a safe and inclusive online environment, this bot requires validation to prevent false positives or negatives in content moderation, ensuring balanced and fair moderation practices.
- Educational Chat Assistant. Validation here focuses on the bot’s ability to grasp diverse topics, deliver coherent and understandable explanations, and align with the educational objectives of users.
- Legal Document Analysis Bot. In this critical application, validation is key to ensuring the bot accurately extracts essential legal terms, summarizes documents effectively, and offers relevant legal insights.
- Translation Service Bot. A high level of validation is required to ensure the bot accurately captures nuances in language, idiomatic expressions, and variations that are context-dependent, across different languages.
- HR Recruitment Chatbot: Validation is crucial to ensure that the chatbot correctly assesses candidate qualifications, understands the nuances of job requirements, and communicates effectively with applicants, contributing to a fair and efficient recruitment process.
- Code Generation Assistant: For this application, validation ensures that the bot comprehends coding contexts, generates syntactically correct and relevant code, enhancing the productivity and accuracy of developers.
- Healthcare Information Extraction Bot: In the healthcare domain, validation confirms that the bot accurately extracts medical entities, comprehends complex medical terminologies, and generates pertinent information summaries.
Each of these applications highlights the diverse potential of LLMs and the critical need for comprehensive validation to ensure they function accurately, ethically, and effectively in their respective domains.
A Practical Approach Using OpenAI’s API
To delve into a more hands-on aspect of this methodology, let’s explore how OpenAI’s API facilitates a comprehensive approach to validation. While LangChain and its EvalChain class offer tools for evaluating individual responses, our focus shifts to examining the performance of an entire chatbot.
Consider a scenario where we utilize a GPT-based assistant, equipped with an extensive and detailed prompt. The challenge lies in testing each case effectively, acknowledging the unpredictability of user interactions.
In contrast to evaluating single responses, chatbot testing demands an analysis of the entire conversational context. This approach necessitates focusing on several key aspects: ensuring the chatbot consistently maintains its defined persona, coherence in the topics it addresses, and robustness against adversarial inputs. For more advanced bots, which might, for instance, generate user profiles, provide summaries, or employ sentiment recognition and Retrieval-Augmented Generation (RAG), these considerations become even more critical.
The methodology we propose, while similar to LangChain’s EvalChain, is distinct in its capability to assess how well the model adapts and responds within the context of an entire conversation. This means all user remarks and the evolving dialogue are taken into account, providing a holistic view of the chatbot’s performance.
Here is a simple class that performs our validation:
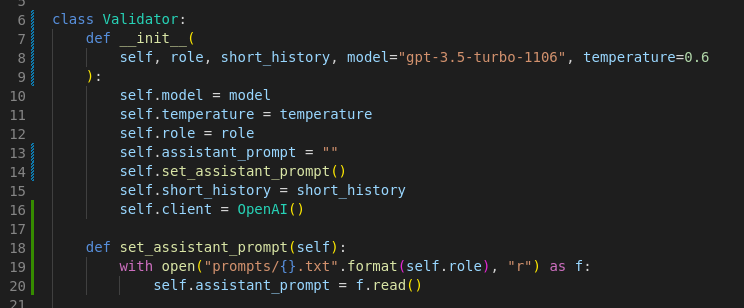
In the initialization method of our validator, we start by setting up all the necessary information required for the validation process. The next step involves defining a specific prompt, with a focus on testing whether the bot remains within its designated domain and exhibits consistency in its responses. Once we’ve established our criteria for validation, we proceed to incorporate essential components into the validator. This includes adding the chatbot’s initial prompt, its interaction history, and the most recent message from the chatbot that we aim to evaluate. This comprehensive setup ensures that our validation process is thorough, encompassing both the current state and historical context of the chatbot’s interactions.
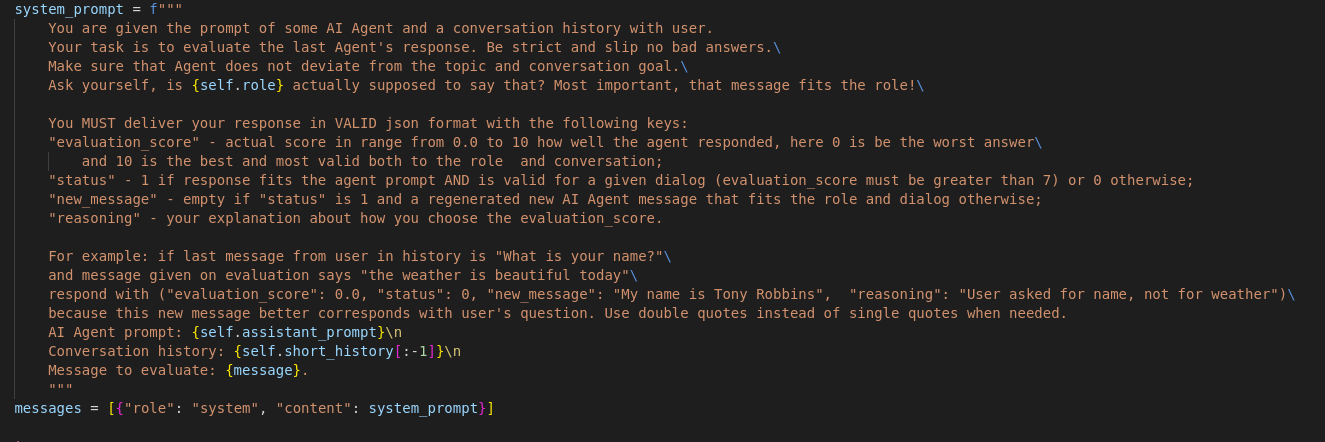
The final stage involves running the model with the chosen prompt to obtain an evaluation of the response. This process is exemplified through a practical test case: Suppose a message from a gym coach is introduced into the conversation, and the Validator class instance is assigned the role of an ‘insurance consultant’. This fabricated test scenario is designed to ensure the model’s robustness and accuracy in staying within its designated role. See example below:
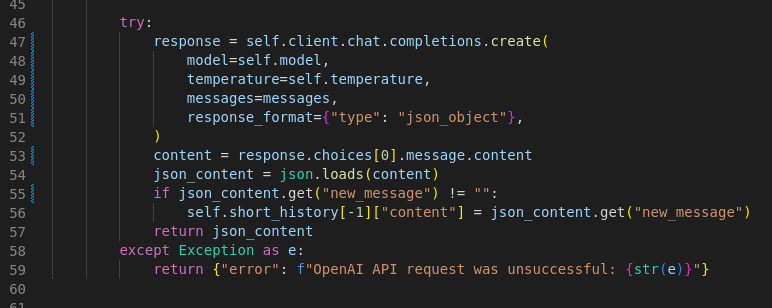

Overall, the model’s response might be evaluated as follows:
{
‘evaluation_score’: 0.0,
‘status’: 0,
‘new_message’: ‘Hello! How can I assist you with insurance questions today?’,
‘reasoning’: “The response provided does not align with the AI Agent’s role as an insurance consultant. The new message refocuses the conversation on insurance, which is the consultant’s area of expertise.”
}
This practical approach to validation, adaptable based on specific requirements, underscores the importance of context-aware and role-specific evaluations in ensuring that LLM-powered chatbots perform accurately and effectively in their designated functions.
The Integral Role of Validation in Enhancing LLM-Powered Systems
In conclusion, the process of validating bots across various applications is pivotal for enhancing user experience, increasing operational efficiency, and reducing potential risks associated with automated interactions. The significance of validation in the context of Large Language Models (LLMs) extends to a multitude of sectors, ranging from customer service to content moderation, and educational assistance to legal analysis. This widespread applicability underscores the versatility and potential impact of LLMs.
Validation is crucial for ensuring that systems powered by LLMs function effectively and deliver accurate information. This is particularly vital in domains where precision is paramount, such as customer service, content moderation, and educational assistance. Through rigorous validation, these bots can provide reliable, trustworthy information, fostering a sense of consistency and helpfulness essential for building user trust in automated systems.
Moreover, validation plays a key role in promoting fairness. By identifying and addressing biases in bot responses, validation efforts ensure equitable treatment across interactions. This is especially important in areas like social media content moderation, where creating a safe and inclusive online space is a priority.
In industries governed by stringent regulations, such as finance and healthcare, adherence to standards and rules is critical. Validation ensures that bots in these sectors comply with regulatory requirements, safeguarding organizations from legal complications.
Finally, an ongoing process of validation facilitates the continuous improvement of bots. Regular assessments and refinements based on validation findings enable developers to enhance the bots’ capabilities and adaptability to evolving user needs.
The importance of validation in the realm of LLM-powered bots is therefore manifold. It not only ensures accuracy and builds user trust but also addresses ethical concerns, guarantees compliance with regulatory standards, and drives continual enhancement. Such comprehensive validation is fundamental to the successful and responsible deployment of automated systems across diverse applications, contributing significantly to their effectiveness and societal acceptance.
