
-
Contents
- Introduction
- Key Issues Affecting the Quality of Generative AI Systems
- Quality Assurance Strategies to Address Issues Affecting AI Systems
- Harnessing Pre- and Post-Validation Frameworks for AI Quality Assurance
- Utilizing Additional AI Models for Evaluating AI Product Metrics
- Leveraging Third-Party Services to Detect AI System Anomalies
- Utilizing LLM AI Models for Generating Human-Like Scenarios and Queries
- Implementing Workflow Scenarios for Describing and Adjusting Testing Scenarios
- Quality Assurance (QA) Techniques for AI-Based Products
- Conclusion

Introduction
A crucial aspect of developing and deploying AI-based products is a comprehensive understanding of the data that fuels these systems, along with a thorough grasp of the tools used. It is equally important to align these technologies with organizational values to ensure ethical and responsible usage. Recent incidents highlight the significant risks associated with AI errors and underscore the importance of rigorous quality assurance for AI development and deployment.
For instance, in February 2024, Air Canada was ordered to pay damages to one of the passengers after its AI assistant provided incorrect information regarding bereavement fares. Following the chatbot’s advice, the passenger bought tickets believing he could apply for a discount post-purchase, only to have his claim denied. This incident, which led to Air Canada being held accountable for the chatbot’s misinformation, emphasizes the critical need for accurate AI systems.
Similarly, the online real estate marketplace Zillow faced substantial losses and had to wind down its Zillow Offers program after its ML algorithm for predicting home prices led to significant errors. The algorithm’s misjudgments resulted in overestimations, causing a $304 million inventory write-down and a 25% workforce reduction. This case illustrates the financial risks tied to AI inaccuracies in critical business operations.
In the healthcare sector, a 2019 study exposed a significant bias in a widely-used healthcare prediction algorithm, which underrepresented Black patients in high-risk care management programs. The algorithm’s reliance on healthcare spending as a proxy for health needs led to discriminatory outcomes, spotlighting the ethical implications and the necessity for bias mitigation in AI systems.
Moreover, Microsoft’s 2016 incident with its AI chatbot Tay, which quickly began posting offensive content on Twitter due to flawed training data, further exemplifies the challenges in AI training and the importance of safeguarding AI against malicious input.
These examples underline the importance of robust QA processes in the development and deployment of AI systems. Ensuring the accuracy, fairness, and reliability of AI technologies is paramount to harnessing their benefits while minimizing risks.
Key Issues Affecting the Quality of Generative AI Systems
The performance and dependability of AI systems depend on various crucial factors that profoundly influence their functionality. Issues such as the structure and consistency of training and test datasets, inherent biases and ethical considerations, the lack of comprehensive test scenarios, and the challenge of subjective evaluation criteria are pivotal in shaping the effectiveness of generative AI. Let’s examine each of these aspects in more detail.
Structured Issues in Training and Test Data Sets
- Data Inconsistency
Variations in data formats, missing values, or contradictory information within datasets can undermine the AI system’s performance. Inconsistent data leads to inaccurate model learning, requiring extensive preprocessing and data cleaning. Inconsistent data can arise from multiple sources, formats, or collection methods. For instance, data collected from different sensors or devices might have varying units, scales, or time stamps. These inconsistencies can confuse the model during training, leading to unreliable outputs.
- Lack of Truth
The absence of a definitive ground truth or reliable labels in training data is a significant challenge for AI model development/ training. Ground truth refers to the accurate, verified information used as a benchmark to train and evaluate models. Without it, models cannot be trained effectively to produce accurate and trustworthy outputs. This issue is prevalent in domains where labeled data is scarce or expensive to obtain, such as medical imaging or legal documents.
- Bias
Bias in datasets can manifest in various forms, such as selection bias, confirmation bias, or exclusion bias. For example, facial recognition datasets might be biased towards lighter skin tones, leading to poor performance on darker skin tones.
- Ethical Issues
Using sensitive or personal data without proper consent raises ethical concerns. For instance, training models on data scraped from social media without user consent can lead to privacy violations.
Lack of Scenarios in Test Datasets
AI models trained and tested on standard datasets might not perform well in real-world applications due to the lack of comprehensive and diverse testing scenarios. This discrepancy arises because standard test sets often do not capture the full range of possible real-world conditions, leading to models that are brittle and prone to failure when faced with unforeseen situations.
Biased Feedback Data Sets
User feedback is a critical component in refining and improving AI models. However, this feedback can be significantly influenced by the users’ emotional states, leading to biased data that might not accurately reflect the true quality or performance of the service or product being evaluated. This emotional bias can skew the training data, leading to models that do not accurately represent user preferences or satisfaction. For instance, a recommendation system might overemphasize or underemphasize certain features based on skewed user ratings.
If users notice that the system often provides unsatisfactory recommendations or assessments due to biased training data, their trust in the system will decrease.
Revising AI System Evaluation Metrics
As models evolve through training, tuning, and fine-tuning, evaluation metrics need to be updated to ensure they remain relevant. Metrics that were useful early in development might become less informative as the model improves.
Vague Expected Results
In tasks like creative content generation or open-ended question answering, the expected outcomes are often subjective and vague. This ambiguity makes it challenging to evaluate the performance of AI models using binary or strictly quantitative criteria. Such tasks do not have clear-cut right or wrong answers, making it necessary to develop nuanced evaluation methods that can capture the complexity and variability of the outputs.
Measuring Performance without Extra Latency
Evaluating AI systems in real-time applications requires efficient techniques that do not introduce significant delays. For instance, latency-sensitive applications like real-time language translation or stock trading need quick and accurate performance assessments.
Addressing these issues involves a combination of technical solutions, best practices, and continuous improvement processes.
Quality Assurance Strategies to Address Issues Affecting AI Systems
In quality assurance for AI, the validation of models isn’t just helpful – it’s crucial. Through validation, both pre- and post-deployment, stakeholders can ensure their AI-based products are functioning as intended, providing reliable outputs and insights. Today, several frameworks work efficiently in the pre- and post-validation space, helping streamline the machine learning process and ensuring optimal results.
Harnessing Pre- and Post-Validation Frameworks for AI Quality Assurance
Examination of Pre-Validation Frameworks
Pre-validation is a critical stage in quality assurance for AI where models are tested for potential biases or errors before they are integrated and deployed into a system. It’s during this phase that significant issues are spotted and rectified, which improves the model’s final performance.
An efficient tool for pre-validation is TensorFlow Extended (TFX), a production-ready ML platform. TFX allows for robust and repeatable ML workflows via its suite of components, one being the TensorFlow Data Validation. This tool is designed for exploring and validating machine learning data, consequently enhancing the data clarity and quality right from the onset. It’s a significant step in reducing future discrepancies, maintaining model’s precision, and minimizing biases. However, its main limitation lies in its strong dependency on TensorFlow platform, making it less flexible in an environment dominated by other libraries like PyTorch or Keras.
Another useful tool is PyCaret, a low-code ML library in Python. PyCaret simplifies data preprocessing, feature selection, tuning, and model selection in the pre-validation phase, saving your team valuable time. The caveat, however, is that PyCaret sacrifices a degree of control and complexity for simplicity, making it less suitable for models that require very detailed customization.
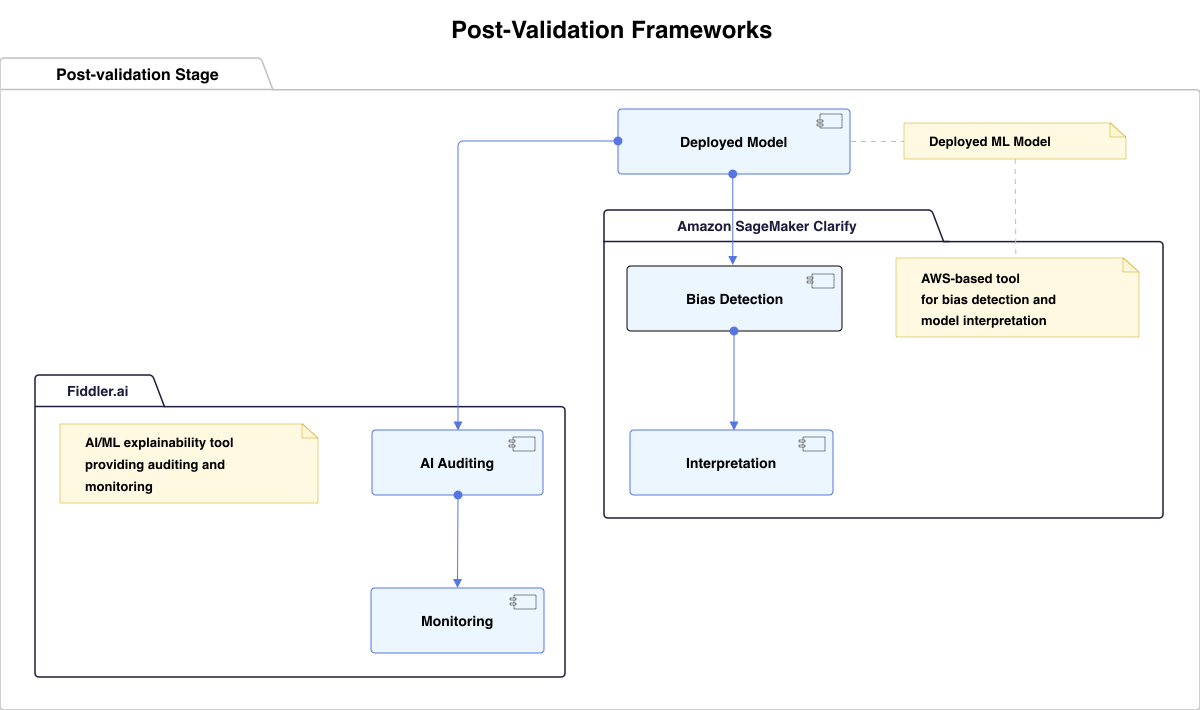
Evaluation of Post-Validation Frameworks
Post-validation, on the contrary, refers to audits done after the system deployment, aiming to check if it performs as anticipated in real-world conditions.
Amazon SageMaker Clarify is one such tool that can offer valuable insights during the post-validation phase. It helps explain model predictions by detecting bias and presenting feature attributions. This allows decision-makers to comprehend how inputs influence the model’s outputs, making complex models more interpretable. However, the adoption of SageMaker Clarify comes with a learning curve, as it requires considerable knowledge in AWS services. Thus, extensive training might be needed for teams unfamiliar with the platform.
Fiddler.ai is another notable tool for the post-validation stage, focusing on the transparency and explainability of AI and ML. Fiddler provides AI auditing and monitoring solutions to ensure models are fair, responsible, and reliable and provide actionable insights. Nonetheless, it may be complex for those new to ML, and its services might be overkill and underutilized in smaller-scale or less critical ML applications.
The Synergy of Pre- and Post-Validation Frameworks in Quality Assurance for AI
In assessing the value of both pre- and post-validation frameworks, we recognize that it isn’t really about identifying which one is more effective. Instead, the focus is on understanding that these frameworks create a comprehensive validation process when implemented together. Pre-validation sets the stage for potential success, while post-validation secures the continued accuracy and integrity of your live AI system.
Processica’s framework for quality assurance for AI employs TensorFlow Extended (TFX) and PyCaret during the pre-validation phase. For robust ML workflows, TFX’s TensorFlow Data Validation ensures smooth progression through data cleaning, analysis, and model training. For simpler models and rapid prototyping, PyCaret facilitates quick, high-quality model generation.
Post-deployment, the framework uses Fiddler.ai for transparency and bias checking, and Amazon SageMaker Clarify for making refined adjustments based on field data. This hybrid approach ensures optimal performance of the AI system and makes complex ML processes understandable and accessible.
Utilizing Additional AI Models for Evaluating AI Product Metrics
At Processica, we’ve pioneered an innovative approach to address quality challenges in AI systems – additional AI models specifically designed for evaluation purposes.
This method involves deploying specialized AI models that work in tandem with the primary AI system to continuously assess and validate its outputs. These evaluation models are trained on diverse datasets and programmed with specific criteria to measure key performance indicators. By doing so, we create a multi-layered quality assurance framework that can adapt to the nuanced and often unpredictable nature of generative AI outputs.
The process begins with the primary AI system generating responses or completing tasks. These outputs are then fed into the evaluation AI systems, which analyze them based on predefined metrics. For instance, one model might focus on assessing the factual accuracy of the information, while another examines linguistic consistency and coherence. Additional models could be dedicated to detecting potential biases or ethical concerns in the generated content.
For instance, we regularly implement this approach in our AI bot testing pipeline. Our evaluation models are designed to simulate various user interactions and assess the bot’s responses across multiple dimensions. This includes checking for contextual relevance, maintaining consistent persona attributes, and ensuring adherence to safety guidelines. The evaluation models provide real-time feedback, allowing for immediate adjustments and fine-tuning of the primary AI bot.
One of the key advantages of this method is its scalability and adaptability. As new challenges or requirements emerge, we can develop and integrate additional evaluation models to address specific concerns. This modular approach ensures that our quality assurance process remains robust and up-to-date with the latest standards and expectations in AI performance.
Moreover, by utilizing AI for evaluation, we can process vast amounts of data and interactions at speeds far surpassing human capability. This allows for comprehensive testing across a wide range of scenarios, uncovering potential issues that might be missed in traditional QA processes. The AI-driven evaluation also provides quantifiable metrics and detailed reports, enabling data-driven decision-making in the development and refinement of AI products.
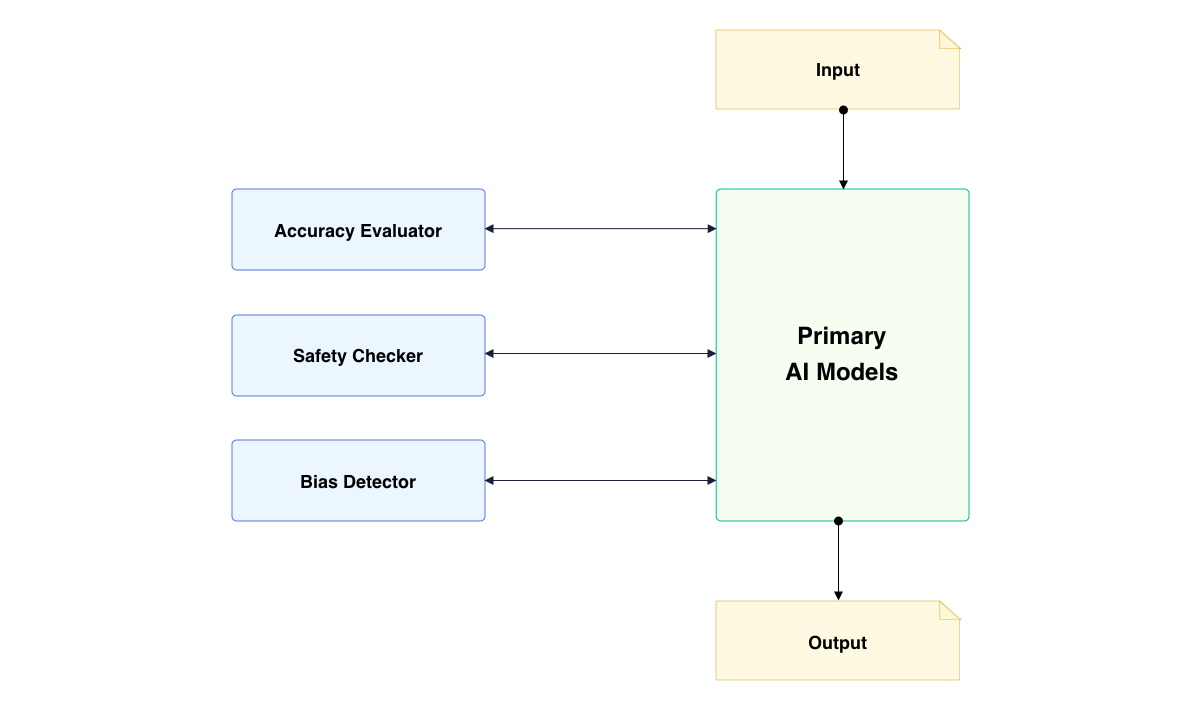
In conclusion, the use of additional AI models for evaluation represents a significant leap forward in ensuring the quality and reliability of AI-based products. At Processica, this approach has not only enhanced the performance of our AI bots but has also instilled greater confidence in our clients regarding the safety and effectiveness of our AI solutions. As we continue to refine and expand this methodology, we anticipate even more sophisticated and comprehensive quality assurance processes for the next generation of AI systems.
Leveraging Third-Party Services to Detect AI System Anomalies
In the world of AI systems, anomalies are not mere inconveniences, but critical events that can impact both the model’s output and the larger system operations. Leveraging third-party services for the detection of these anomalies presents a valuable strategy in maintaining the integrity of AI systems. These services take on the role of a vigilant watcher, ready to raise a red flag upon detection of any inconsistency, allowing the system or users to react accordingly.
Third-party services such as DataRobot or Kibana play a vital role in identifying anomalies in an AI system’s output. For instance, DataRobot uses automated machine learning and AI to effectively detect anomalies in vast datasets. Similarly, Kibana provides visualization capabilities on Elasticsearch data, an essential tool for spotting anomalous patterns visually.
Utilizing these services offers various advantages. It can significantly reduce the time spent on manual checks, and these platforms often feature high-level accuracy in their anomaly detection outputs. However, these can also present limitations – such as dependency on external resources and potential dexterity issues when it comes to customizing to specific model needs.
Third-Party Services and System Red Flags
System red flags function akin to an early warning within an AI system. They identify and flag abnormal behavior, which is particularly critical in real-time models where any deviance warrants immediate action. Splunk’s Machine Learning Toolkit exemplifies this functionality brilliantly. Its system uses the advanced anomaly detection algorithm LOF (Local Outlier Factor) to establish models of normal behavior and yields red flags whenever the behavior boundaries are breached. This greatly reduces the risk of model failure and helps maintain overall system stability.
Another service that excels at system red flag handling is Grafana – it’s not only a powerful anomaly detection tool but also an effective visual dashboard for data reporting. Grafana, when paired with Zabbix for data collection, can monitor nearly every aspect of the system, from CPU usage and memory consumption, to application performance, showing red flags when metrics go beyond established thresholds.
The use case of Twitter serves as an ideal example. Twitter leveraged a sophisticated system of anomaly detection and red flags, and when anomalies were detected in user engagement numbers, they could be notified, scrutinize the issue, and rectify it promptly. The integration of red flags indeed brought a transformative change in maintaining system stability in real-time applications.
Integrating Third-Party Services into Existing Systems
The integration of third-party services into existing AI systems is a deliberate process that requires meticulous planning and execution. The first step generally involves aligning the chosen service with the organizational objectives. For example, using DataRobot for automating ML and anomaly detection would be a strategic choice for organizations aiming for rapid model development without extensive coding efforts.
The next step, configuring the service with the AI system, can be exemplified by integrating ElasticSearch with Kibana. ElasticSearch acts as a search engine offering full-text search capabilities, while Kibana visualizes the data. When coupled together, they provide a comprehensive view of anomalies by creating interactive visualizations and dashboards from the model’s data.
After configuration, service testing is crucial. For example, trials of the anomaly detection service, like Amazon’s GuardDuty, can be performed to ensure its efficiency and compatibility with the existing model. Its findings can be compared with other services like Azure’s Advanced Threat Protection to ensure maximum anomaly detection efficiency.
One must be prepared to face challenges, which might include compatibility issues between the service and your system or escalating costs. Also, the reliance on third parties for system monitoring could raise concerns about data privacy. However, tackling these challenges through meticulous selection, effective planning, regular reviews, and constant communication with service providers will foster successful integration, ensuring optimal AI system performance.
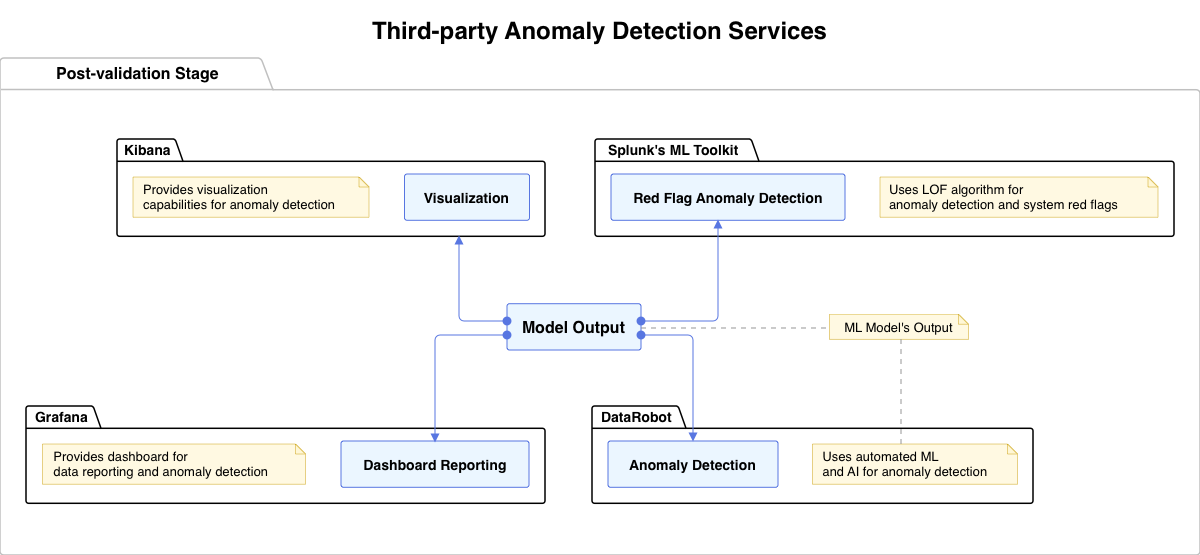
In conclusion, third-party services have proven invaluable in detecting anomalies and facilitating the functionality of system red flags. At Processica, we prioritize real-time anomaly detection in AI systems by leveraging sophisticated third-party services for optimal performance. Our Flow Engine orchestrates processes by communicating with these services and feeding data into anomaly detection models, ensuring continuous monitoring.
Utilizing LLM AI Models for Generating Human-Like Scenarios and Queries
In the realm of quality assurance for AI, one of the most challenging aspects is creating diverse, realistic, and comprehensive test scenarios that mimic genuine user interactions. At Processica, we’ve pioneered an innovative approach to address this challenge by leveraging Large Language Models (LLMs) to generate human-like scenarios and queries for quality assurance for AI and have successfully applied it to test AI bots.
This method involves training specialized LLMs to act as virtual users, each with unique personas, communication styles, and interaction patterns. These AI-powered testers engage with our bots in conversations that closely resemble real-world interactions, allowing us to evaluate the bot’s performance across a wide spectrum of scenarios that might be difficult or time-consuming to create manually.
The process begins with defining a set of testing objectives and parameters. These may include specific use cases, edge cases, or particular aspects of the bot’s functionality that require thorough examination. We then prompt our testing LLMs with these parameters, instructing them to generate a series of interactions that align with our testing goals.
As the LLM-generated “users” engage with our AI bots, they produce a wealth of diverse scenarios. These can range from straightforward queries to complex, multi-turn conversations that test the bot’s ability to maintain context, handle ambiguity, and provide consistently accurate and relevant responses. This approach allows us to uncover potential issues that might not be apparent in more structured, predetermined test cases.
At Processica, we’ve implemented this method in our AI bot testing pipeline with remarkable success. We use a specially prepared ‘family’ of LLMs, each designed to interact with our bots from different perspectives. For instance, one LLM might simulate a tech-savvy user with complex queries, while another mimics a user with limited technical knowledge, helping us assess the bot’s ability to adapt its communication style.
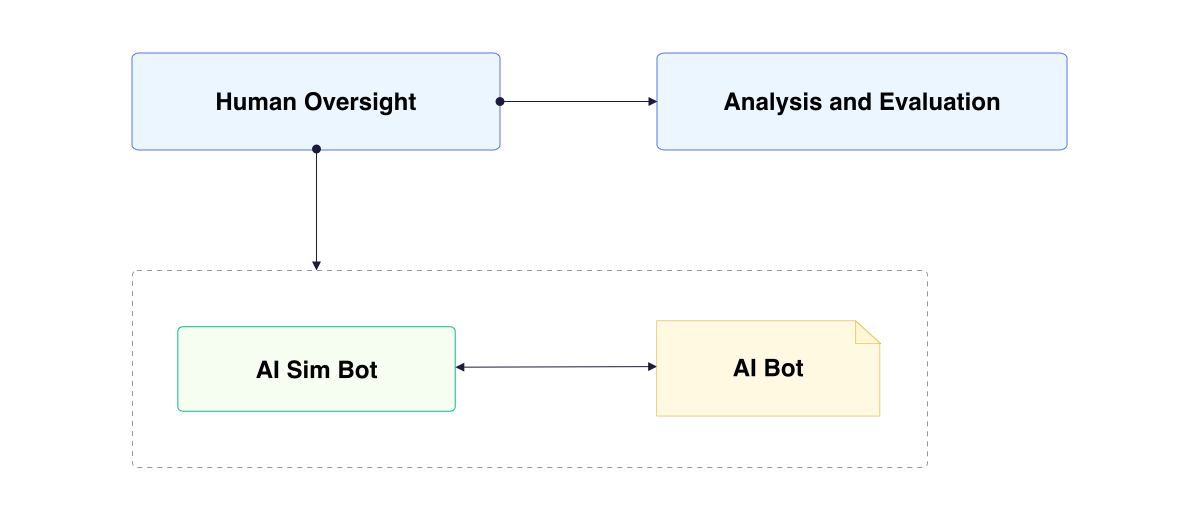
The next step in this process involves human oversight. Our developers observe these AI-to-AI interactions, analyzing the conversations for any anomalies, inconsistencies, or areas where the bot’s performance could be improved. This human-in-the-loop approach ensures that we don’t miss nuanced issues that might escape purely automated evaluation methods.
Furthermore, we’ve found that combining this LLM-based testing approach with other QA methods, such as the AI model evaluation technique described in section 2.1, creates a powerful, multi-faceted quality assurance process. The LLM-generated scenarios provide the raw interaction data, which can then be fed into our evaluation models for deeper analysis across various metrics.
This innovative use of LLMs for testing has significantly enhanced our QA process at Processica. It allows us to rapidly generate and execute a vast number of test cases, covering a broader range of potential user interactions than traditional methods. Moreover, as language models continue to evolve, so does the sophistication and realism of our test scenarios, ensuring that our AI bots are always prepared for the complexities of real-world deployment.
In conclusion, the use of LLMs to generate human-like scenarios and queries represents a significant advancement in AI system testing. It not only improves the breadth and depth of our quality assurance processes but also helps ensure that our AI bots are robust, versatile, and truly ready to meet the diverse needs of our users in real-world applications.
Implementing Workflow Scenarios for Describing and Adjusting Testing Scenarios
Processica has developed one more innovative method that brings a new level of dynamism and precision to the testing process. Our proprietary “Workflow Stages” functionality, initially designed to manage AI bot behavior scenarios, has evolved into a powerful tool for QA, offering a flexible and adaptive approach to testing AI systems.
The core concept of this method revolves around defining and dynamically selecting the most appropriate testing scenario based on the current state and context of the AI system under evaluation. This approach allows for a more nuanced and responsive testing process, capable of adapting to the intricacies of complex AI interactions.
At the heart of this functionality is a specialized LLM query system. This system analyzes the current circumstances and state of the conversation or interaction, then selects the most suitable scenario from a pre-prepared archive. In the context of QA, this translates to an ability to dynamically adjust testing parameters and focus areas based on real-time performance and behavioral patterns of the AI system.
The process begins with the creation of a comprehensive archive of testing scenarios, each designed to evaluate specific aspects of the AI system’s functionality, performance, or behavior. These scenarios are not static but are structured as flexible workflows that can be adapted on the fly. As the testing progresses, the LLM continually assesses the AI system’s responses and overall performance, making decisions about which testing path to pursue next.
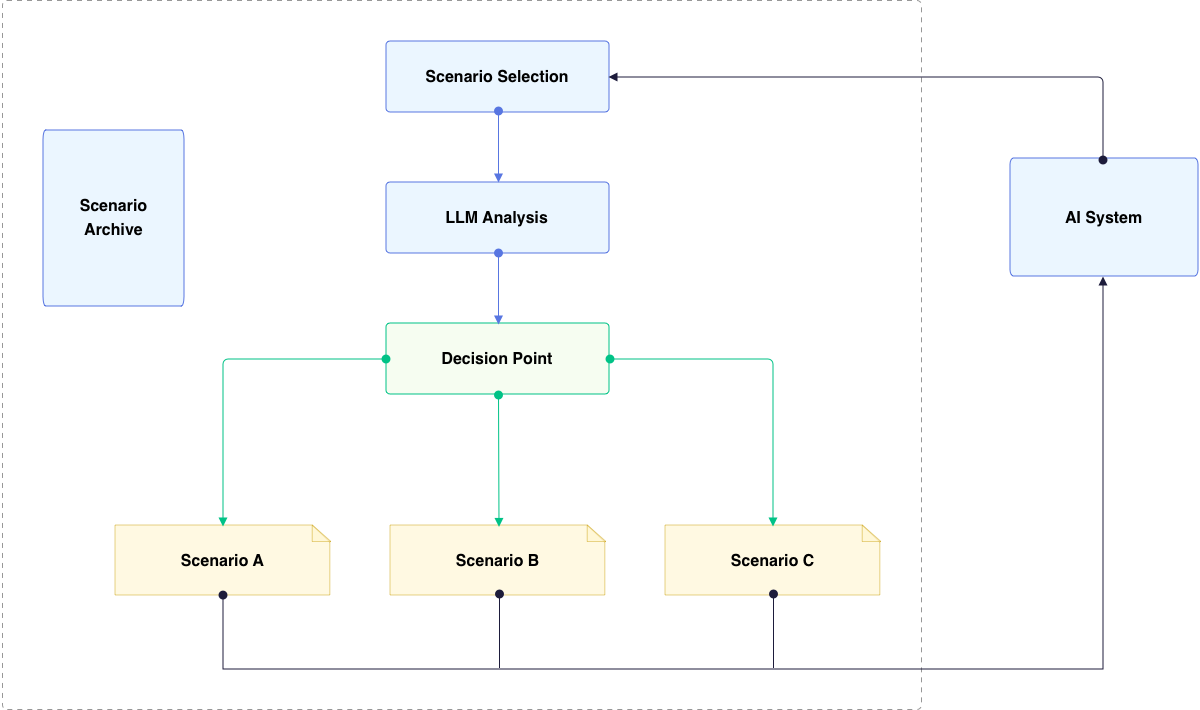
One of the key advantages of this approach is its ability to uncover edge cases and unexpected behaviors that might be missed in more rigid testing frameworks. By allowing the testing process to evolve based on the AI system’s responses, we can explore branches of interaction that weren’t initially anticipated, leading to more thorough and insightful quality assurance.
Moreover, this method excels in evaluating the consistency and contextual awareness of AI systems. As the workflow progresses through different stages, it can test the AI’s ability to maintain coherence across varying contexts and complexities of interaction. This is particularly crucial for ensuring that AI bots and systems can handle the unpredictable nature of real-world user interactions.
At Processica, we’ve found that this workflow approach significantly enhances our ability to fine-tune and optimize AI systems. The dynamic nature of the testing process provides rich, contextual data about system performance, allowing for more targeted improvements. It also helps in identifying subtle issues that might only emerge in specific sequences of interactions, which are often difficult to predict and test for using traditional methods.
Furthermore, this method has proven invaluable in testing the adaptability of AI systems. By simulating various workflow paths, we can assess how well the system adjusts to changing user needs, contexts, and complexities – a critical factor in the real-world application of AI technologies.
In conclusion, the adaptation of our “Workflow Stages” functionality for QA purposes represents a significant advancement in AI system testing. It offers a more dynamic, context-aware, and comprehensive approach to quality assurance, ensuring that our AI systems are not just functional, but truly adaptive and robust in the face of diverse and complex user interactions. As we continue to refine and expand this methodology, we anticipate even greater insights and improvements in the quality and reliability of AI systems.
Quality Assurance (QA) Techniques for AI-Based Products
Quality assurance (QA) for AI-based products involves a range of methodologies tailored to specific types of AI systems. Each type of AI application has unique challenges and requirements that necessitate specialized QA approaches to ensure optimal performance, reliability, and user satisfaction. Below, we outline various use cases and the corresponding QA strategies employed by Processica, integrating key techniques to address these challenges.
AI Systems with Internal or External RAG
For AI systems utilizing Retrieval-Augmented Generation (RAG), QA focuses on ensuring the accuracy and relevance of the retrieved data that informs the generative process. This involves regularly verifying the accuracy and completeness of external or internal databases, monitoring the system’s ability to retrieve relevant data efficiently and accurately, and ensuring that the retrieved data consistently enhances the generated content. Techniques such as using TensorFlow Extended (TFX) for robust data validation and preprocessing, PyCaret for simplifying data preprocessing and feature selection, and integrating third-party services like Elasticsearch and Kibana for efficient data retrieval and visualization are employed to maintain data integrity and performance.
Predictive AI Systems
In AI systems generating predictions, robust QA is essential to validate the accuracy and reliability of outputs. This involves model validation through cross-validation and holdout methods, thorough error analysis to identify and mitigate biases or errors, and continuous performance monitoring using metrics such as precision, recall, and F1 score. Techniques include using TFX and PyCaret for data consistency and accuracy, employing Amazon SageMaker Clarify to detect biases, and using Fiddler.ai for model interpretability and reliability.
Conversational AI Systems
Conversational AI systems, such as chatbots and virtual assistants, are tested for their ability to engage in natural, coherent, and contextually appropriate interactions with users. QA strategies include testing dialogue management, evaluating the accuracy of natural language understanding (NLU), and incorporating user feedback to refine conversational models. Techniques involve using large language models (LLMs) to simulate diverse user interactions, implementing dynamic workflow scenarios, and utilizing Fiddler.ai to analyze conversational data.
AI Systems with Assessments and Evaluations
For AI systems used in assessments and evaluations, ensuring precise and unbiased performance is critical. QA strategies include bias detection, regular calibration for scoring accuracy, and fairness audits to ensure equitable evaluations. Techniques involve using TFX for data accuracy and consistency, employing SageMaker Clarify for bias detection, and conducting systematic fairness audits.
AI Systems with a Generative Function
Generative AI systems require rigorous QA to ensure the quality, originality, and appropriateness of generated outputs. QA strategies involve developing and applying quality metrics, implementing ethical and content moderation filters, and testing the system’s performance in diverse real-world scenarios. Techniques include using quality metrics and real-world scenario testing, employing ethical guidelines, leveraging LLMs to create diverse test scenarios, and utilizing PyCaret to simplify the model generation process.
By aligning these QA techniques with specific use cases, Processica ensures a comprehensive and robust quality assurance framework for various AI systems. This approach addresses the unique challenges of each AI application, ensuring reliability, accuracy, and ethical performance across the board, thereby maintaining the integrity and trustworthiness of AI technologies in real-world deployments.
Conclusion
In today’s rapidly evolving technological landscape, the integration of AI and machine learning has become pivotal for organizations seeking to innovate and gain a competitive edge. However, with the exponential growth in AI adoption comes an equally significant need for robust quality assurance (QA) frameworks. Recent incidents, such as those involving erroneous AI recommendations in aviation and real estate, underscore the critical importance of ensuring AI systems are accurate, reliable, and ethically sound.
Processica’s approach to AI QA represents a paradigm shift from traditional testing methods, offering a comprehensive suite of strategies tailored to the complexities of modern AI applications. Central to this framework is the synergy between pre-validation and post-validation techniques. Pre-validation utilizes tools like TensorFlow Extended (TFX) and PyCaret to meticulously validate data integrity, preprocess information, and optimize model performance from the outset. This proactive approach not only enhances the accuracy of AI models but also reduces bias and ensures the reliability of outputs.
Post-validation, on the other hand, involves continuous monitoring and refinement using tools such as Fiddler.ai and Amazon SageMaker Clarify. These tools enable Processica to analyze model predictions, detect biases, and ensure interpretability, thereby enhancing transparency and accountability in AI decision-making processes. By combining these approaches, Processica creates a robust feedback loop that supports ongoing improvement and adaptation of AI systems to real-world conditions.
Moreover, Processica’s pioneering use of additional AI models for evaluation purposes represents a significant advancement in QA methodology. By deploying specialized AI testers trained on diverse datasets, Processica simulates a wide range of user interactions to evaluate AI performance across various scenarios. This innovative approach not only accelerates testing cycles but also uncovers nuanced issues that traditional QA methods may overlook, ensuring AI systems are resilient and adaptable.
Furthermore, Processica integrates third-party services for anomaly detection and system stability, such as DataRobot, Kibana, and Grafana. These tools provide real-time insights into AI system behaviors, allowing for immediate identification and mitigation of anomalies that could impact performance or reliability. This proactive monitoring approach minimizes downtime, enhances system efficiency, and bolsters overall user confidence in AI-driven solutions.
Processica has developed robust Quality Assurance (QA) strategies tailored to the complexities of AI models based on Large Language Models (LLMs) and generative technologies. Our approach begins with automated testing modules that simulate human interactions to rigorously evaluate model responses across diverse queries. This ensures coherence, relevance, and accuracy at scale, supported by automated evaluation mechanisms.
Recognizing the diversity in AI model architectures, including Retriever-Augmented Generation (RAG) and fine-tuning variations, we employ comparative analysis to identify models that best fit specific client needs and operational contexts. Stress testing methodologies further validate model performance under high-demand scenarios, enhancing reliability and resilience.
In conclusion, while AI technologies promise unprecedented advancements in efficiency and innovation, their successful deployment hinges on effective QA practices. Processica’s holistic QA framework not only addresses current challenges but also anticipates future trends, ensuring AI systems are not only technically proficient but also ethical, transparent, and aligned with organizational goals. By continuously refining its methodologies and embracing cutting-edge tools, Processica remains at the forefront of AI QA, setting new standards for excellence in AI system reliability and performance.
