
-
Contents
- Introduction
- Types of LLMs
- Mastering Closed (Proprietary) LLMs
- The Specifics of Open (Open-Source) LLMs
- Comparative Analysis of Closed and Open LLMs
- Navigating the Choice Between Proprietary and Open-Source LLMs Based on Specific Needs and Constraints
- Use Cases and Applications of LLMs - Exploring Diverse Scenarios
- Future Trends and Predictions in LLM Development
- Concluding Thoughts

Introduction
Types of LLMs
LLMs can be broadly classified into two main categories:
1. General-purpose models have the capability of performing various tasks in multiple domains.
2. Specialized models are developed to be used in certain domains or for certain purposes like in the medical field, law, or business.
Additionally, LLMs can be categorized based on their accessibility and licensing:
1. Proprietary (closed) models that are developed and controlled by private companies, with limited access and usage rights.
2. Open-source models that are that are freely available for use, modification, and distribution by the community. .
Proprietary LLMs are usually created by large IT companies or dedicated AI companies. These models inherently have some of the best performance available but with limitations on their usage, configuration, and distribution. Some of them are GPT-4o developed by OpenAI and Claude 3. 5 by Anthropic.
As for the open-source LLMs, they are built collectively by the researchers or published by some organizations. These models offer greater transparency, customization options, and community-driven improvements. Notable examples include LLama 3, Falcon, and more recently, models like Mistral and Gemma.
Today’s LLM scene is based on the constant competition between these proprietary and open-source approaches, which have their advantages and drawbacks as well as the potential for AI’s future evolution.
Mastering Closed (Proprietary) LLMs
The three absolute leaders in the world of LLMs, according to the LMSYS Chatbot Arena Leaderboard, are GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro – all of which are proprietary models
Proprietary LLMs are custom-made by private companies and the usage of these LLMs is well governed by such companies. This approach has created a very progressive development in the field, as players like OpenAI, Anthropic, and Google keep on experimenting with the possibilities of Natural Language Processing. The methods used to manage proprietary models and their updates conform to the concept of enhancement and protection of competitive advantage. These companies allocate large sums of money towards the research and development of their machine learning models, using large amounts of data and computation to train them and find errors.
To illustrate the current state of proprietary LLMs, let’s compare the top models across various performance metrics:
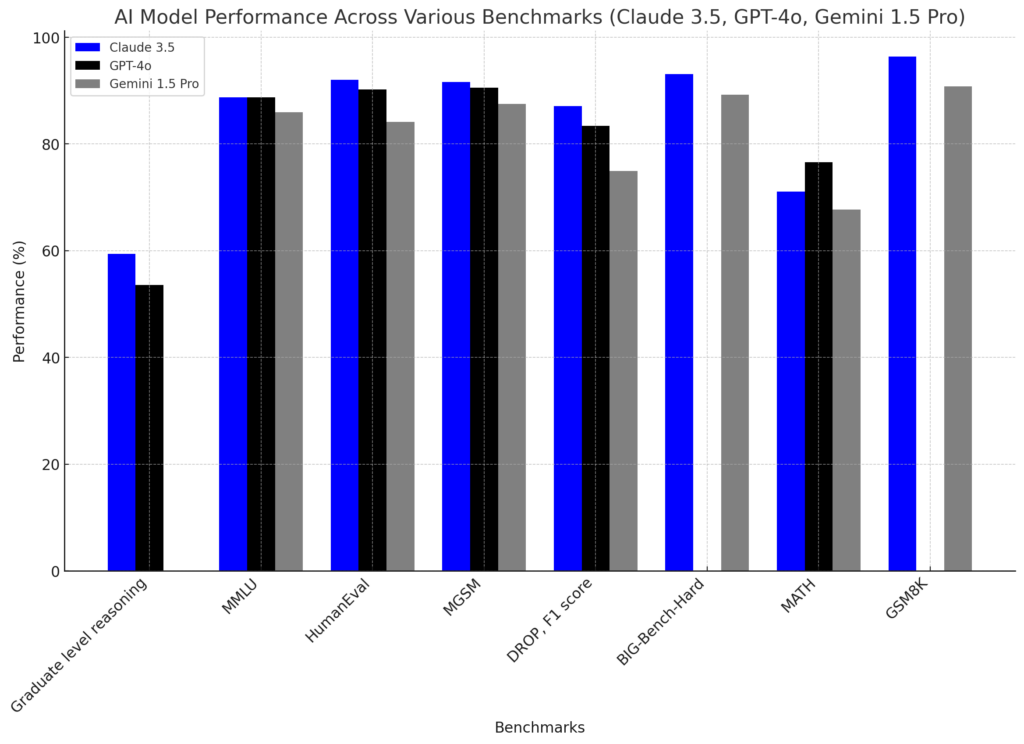
From the data that has been produced, what we can see is that Claude 3. 5 Sonnet leads in most categories, which indicates the intense rivalry and advancement in the proprietary LLM market.
Advantages of Proprietary LLMs
1. Cutting-edge performance. These models are also always in line with the current standards in as far as benchmarking is concerned.
2. Increased ease of development processes to the end users. Firms offer APIs and platforms to enable developers to incorporate such strong models into their apps easily.
3. Regular updates and improvements. Custom models are subjected to constant updates and addition of new features.
4. Robust support and documentation. Firms usually provide extensive information to help developers harness the models availed by the firm.
Disadvantages of Proprietary LLMs
1. Cost. Unfortunately, access to such models is costly, especially for a start-up firm or independent programmer.
2. Closed ecosystem. Customers have a limited number of options and functions to work with, and those options are strictly defined by the company.
3. Potential bias. It is not clear often what training data and methodologies are used and there tends to be questions on the inherent biases in these models.
4. Data privacy concerns. Some proprietary models involved sharing some of the organization’s data with the model providers, thus posing privacy and security risks.
5. Dependency on the provider. Consumers depend on the company’s support and availability of the model; this is a weakness.
Proprietary LLMs represent the current pinnacle of natural language processing technology, offering unparalleled performance and ease of use. However, their closed nature and associated costs present challenges that have led to growing interest in open-source alternatives, which we’ll explore in the next section.
The Specifics of Open (Open-Source) LLMs
Currently, the availability of open-source LLMs is growing rapidly and the count of models available on such platforms as Hugging Face has exceeded 100 thousand. Although today’s most popular open-source models like LLama 3 and Mistral rank a bit lower than their proprietary counterparts in the LMSYS Chatbot Arena Leaderboard, they are gaining on their competitors rapidly and have certain perks.
To illustrate the current state of open-source LLMs, let’s first compare three smaller-scale models:
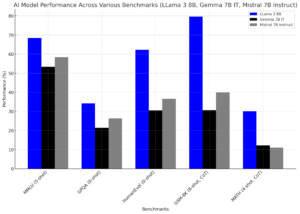
As we can see, even among smaller open-source models, there is significant variation in performance across different tasks. LLama 3 8B shows particularly strong results, especially in code generation and mathematical reasoning tasks.
To put open-source models in perspective with proprietary ones, let’s compare GPT-4o with LLama 3 400B:
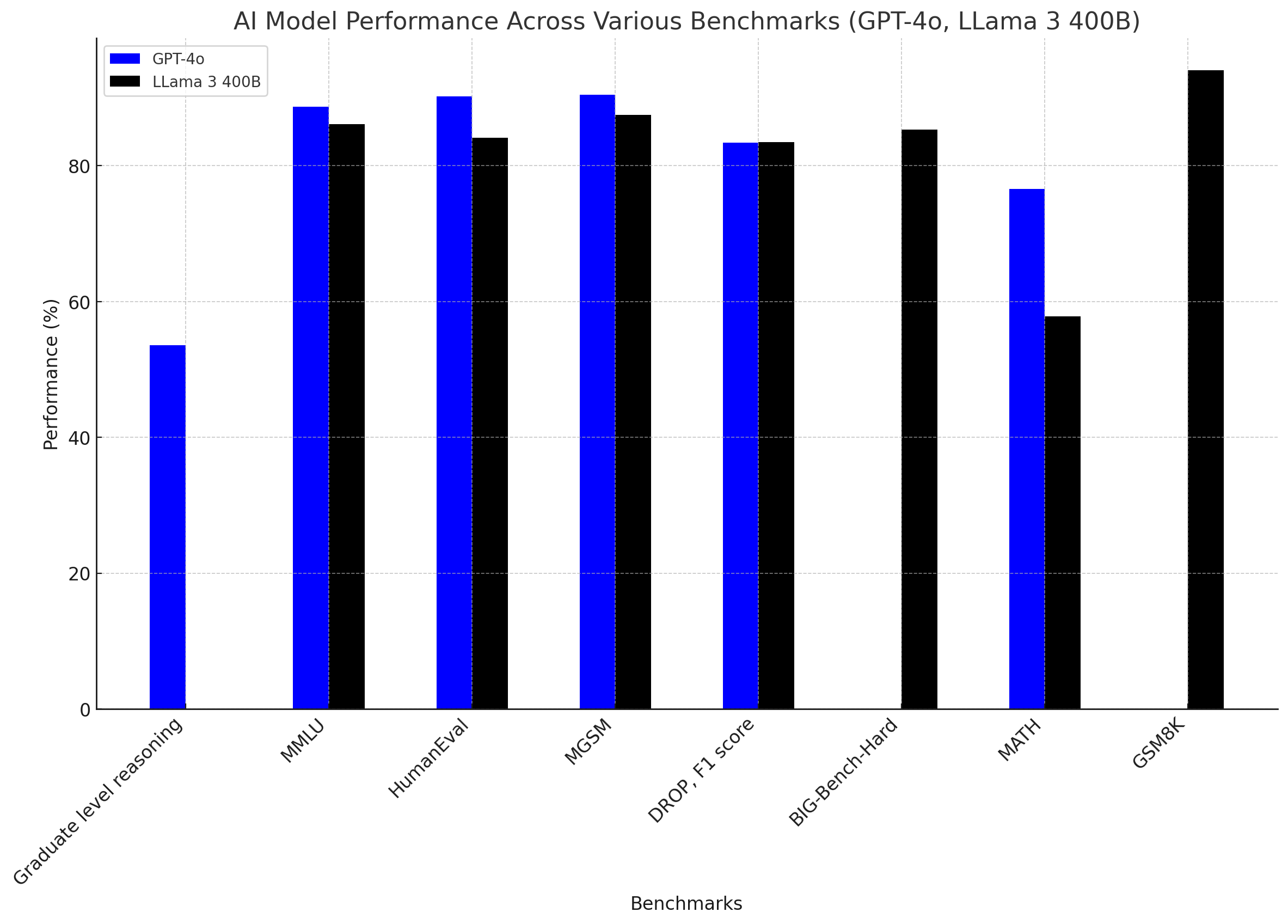
Compared to GPT-4o, LLama 3 400B might be slightly worse in most of the aspects, but it performs rather well, especially in reasoning based on the given text, and simple grade school math. To this end, this comparison reveals the type of progress that is currently being made in the open-source LLM domain.
The open-source LLM movement has been accelerated with models such as BERT and GPT-2. Some of the significant players in this domain are Meta which has developed the LLama series, Google with models such as BERT and T5, and relatively a few organizations such as Mistral AI. The way of developing and updating the open-source is also quite different where people from all over the world can participate in the research, development, and enthusiasts.
The nature of open-source LLMs is based on the principles of openness, cooperation, and availability. These models are:
• Publicly available for use, modification, and distribution
• Often smaller in parameter count compared to proprietary models, focusing on efficiency
• Continuously improved through community efforts.
Advantages of Open-Source LLMs
1. Transparency. The architecture of the model, used data, as well as methodologies are transparent, and thus biases can be easier to track and reduce.
2. Customization. Users can optimise the models in certain tasks or in certain areas of applications.
3. Community support. Many developers are involved in enhancing, correcting, and creating new uses for it because it is a massive ecosystem.
4. Cost-efficiency. Most of the open-source models can be trained either on personal computers or on low-cost cloud environments.
5. Privacy. The user’s information can be processed on the device without transmitting to other servers or organizations.
Disadvantages of Open-Source LLMs
1. Performance gap. Despite the fact that the open-source models are quickly catching up, they might be slightly behind some of the best proprietary models as per some benchmarks.
2. Maintenance challenges. Staying abreast of progress, let alone maintaining the model’s stability, can be consuming, time-wise as well as financially.
3. Limited resources. Open-source projects might be less funded and computational as against the large tech firms in the market.
4. Fragmentation. The availability of a variety of models increases the number of open-source ones and, consequently, weakens the overall structure, making it difficult to select an appropriate model for a certain problem.
Despite the fact that open-source LLMs may not have the same high-level performance as the best proprietary models at the moment, they have features that are instrumental in specific situations. However, given the openness, active advancement, and collective work of open-source development, this gap might be expected to close further in the years to come, thus altering the LLM environment.
Comparative Analysis of Closed and Open LLMs
When evaluating proprietary and open-source LLMs, several key factors come into play. This analysis aims to provide a comprehensive comparison to guide decision-making processes for organizations and developers.
Performance and Capabilities
Despite the fact both types of LLMs are AI driven and fit numerous applications, there are more advanced AI results provided by proprietary models at the moment. However, open source models are quickly closing the gap as we have seen benchmarks earlier in this document.
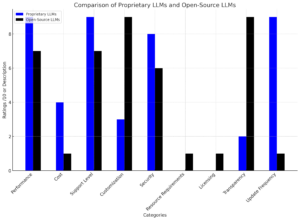
Cost Implications and Resource Requirements
Proprietary LLMs are usually associated with the constant costs charged through API calls or subscription plans, which can be from $0.01 to $0.10 per 1K tokens for APIs, or $0.20 – $500+ per month for subscriptions. Solutions for the enterprise begin at $10K+ per month. These models can be used with very few local resources apart from internet access and time from the developer to integrate them.
Open-source LLMs, while free to use, incur infrastructure costs (100−100−1000+ per month depending on usage) and may require a significant upfront investment in powerful GPUs (5K−5K−50K+). They offer flexibility in deployment but demand more technical expertise for setup and maintenance.
Licensing and Legal Considerations
Proprietary models are restricted by licensing which does not allow modification and or even distribution. There is less restriction in the usage, modification, and distribution of open source models since they come along with liberal licenses though there is always a condition that the person using the open source models has to obey certain open source licenses.
Security and Reliability Concerns
Proprietary licensed LLMs come with managed security services and consulting services, which may be more reliable than the public ones. Models that are open source tend to rely on the organization to manage their own security, which can be both a weakness and a strength depending on the firm’s security requirements. To visualize the unique and shared attributes of both types of LLMs, consider the following Venn diagram:
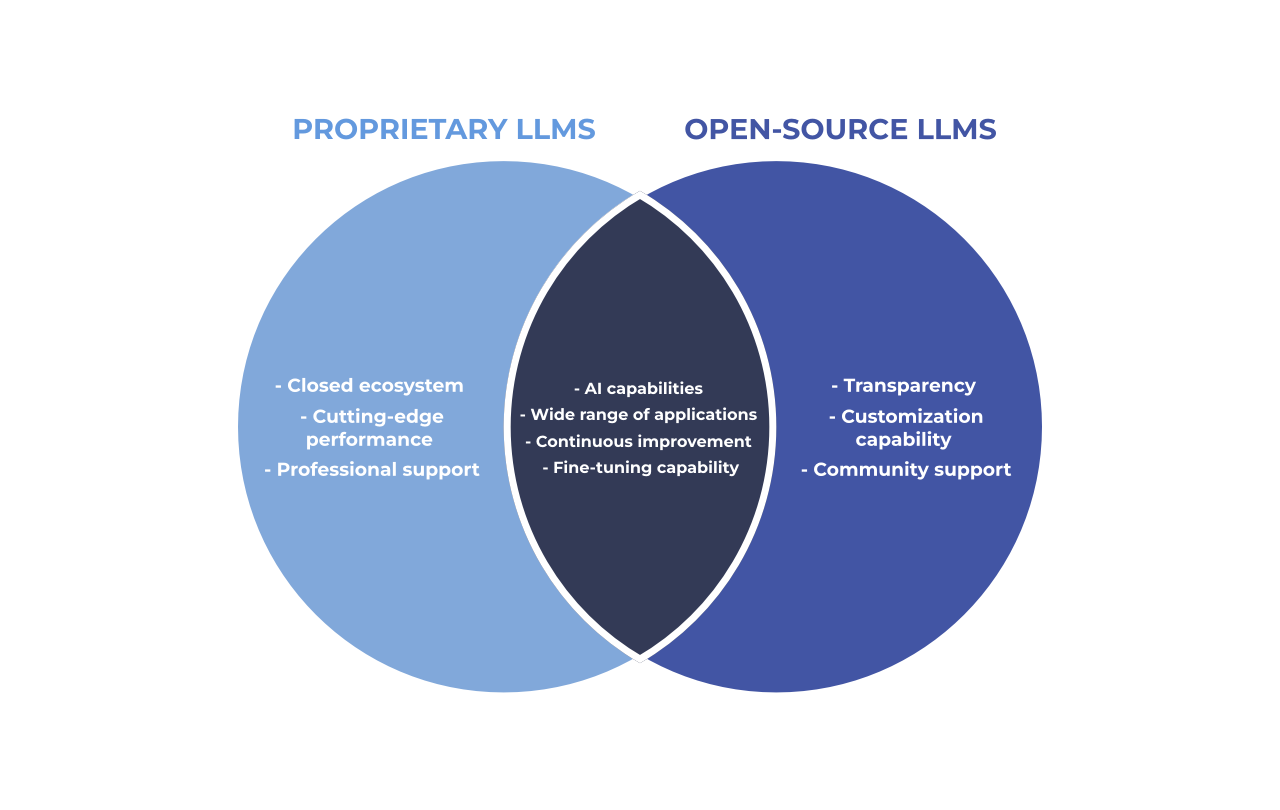
Navigating the Choice Between Proprietary and Open-Source LLMs Based on Specific Needs and Constraints
The decision between proprietary and open-source LLMs hinges on particular requirements and limitations.
Choose proprietary LLMs when:
- Cutting-edge performance is crucial
- Professional support and managed security are required
- Resources for infrastructure management are limited
Choose open-source LLMs when:
- Customization and transparency are paramount
- Cost-effectiveness is a priority
- In-house expertise for model management is available
Finally, it should respond to an organization’s technical and financial capabilities and to specific application needs. There may be instances where an optimal solution is a combination of both the types of models.
Use Cases and Applications of LLMs - Exploring Diverse Scenarios
The decision of whether to go for proprietary or open-source LLMs plays a very important role in determining the final output or service. Each type is best suited for different sectors, and this is why the choice usually depends on the characteristics of a particular project.
Proprietary LLMs are best suited in highly performance-oriented and easy-to-develop applications. For instance, GPT models from OpenAI are used by many chatbots and content-generation solutions in various fields. These models are most suitable when the project requires quick implementation and a quick increase in capacity.
Thus, open-source LLMs excel in situations that require transparency and flexibility. NASA and IBM have used open-source models for certain scientific and technical purposes, and therefore they were able to train the models separately. In the healthcare domain, open-source LLMs are used for tasks that require interpretation such as analyzing medical records for diagnosing and developing new drugs, and here, the reasoning behind the model’s decisions is paramount.
As far as the decision between closed and open models is concerned, the issue depends on the individual characteristics of a particular project. Thus, the decision to choose open-source LLMs applies if your project requires high levels of flexibility and transparency and if you’re willing and able to host and manage the model. On the other hand, if performance and development simplicity are more important factors for your business, then a proprietary LLM might be suitable for you.
Future Trends and Predictions in LLM Development
Competition in the LLM field at the moment is high, and this has led to this field developing at a very high rate. As Olive points out, this melting pot of innovation is not conducive to long-term forecasting. However, looking at the current trends and experience, we can expect the following changes.
Emerging Technologies and Their Impact
There are some invigorating trends that define the forthcoming trends of LLMs. Multimodal AI is a step up from the previous generation, it allows LLMs to combine text, image, and audio functionalities.
Quantum computing has the potential of bringing drastic changes in the LLMs field as it has the ability to build quantum models with tremendous enhancement in efficiency and performance.
Moreover, Edge AI is pushing advancements in designing lightweight, efficient LLMs, specific to on-device solutions that improve speed and privacy in decentralized settings. These trends show continued progress still emerging, which has the potential to revolutionize existing LLMs and their functions in various industries.
Market Dominance
It becomes hard to forecast that one type will exclusively overpower the other but both, the proprietary and open-source LLMs will continue to coexist and thrive in their respective specialties.
Specialized LLMs should continue to provide the best performance and convenience for enterprise applications in terms of novelty. The following predictions can be made for open-source LLMs: their future demand will increase where clients need specific outcomes; their future demand will increase in the field where transparency is critical.
In the future, there will be 2-3 players per category, such as models dedicated to specific application fields. It is expected that the independents will keep progressing and promoting the uses of AI to the general public, while the closed ones will stick to high-performance and specific business applications. That is why it is possible to speak about the future development of cooperation between open-source and proprietary models, including the progressive use of their synergistic solutions as a result of the interaction of both models.
Concluding Thoughts
Large Language Models are an important part of the current state of artificial intelligence and have a wide variety of applications; both closed-source and open-source LLMs contribute to the progress of the field. At present, the proprietary models such as GPT-4, Claude, and Gemini are superior in terms of their performance metrics; however, the open-source rivals are improving fast and come with certain advantages that have been discussed above.
Generally, it is possible to conclude that the decision to use a proprietary or open-source LLM depends on specific circumstances related to its application, available resources, and organizational requirements. Proprietary ones are best for situations where maximum performance and simplicity of usage are the keys to success, while open-source ones are best used when the transparency of the model, its customization, and the ability to improve it with the help of the community are crucial.
To get professional advice on these choices and on how to optimally use LLMs for your projects, contact Processica. Being an expert team in AI application and custom development, Processica offers solutions that best fit your needs for AI enhancement.
