
-
Contents
- Three Phases of Augmenting Developer Productivity
- Onboarding and Support with AI - Enhancing Developer Integration and Efficiency
- Detailing RAG for Language Model Integration in Development Support Systems
- RAG Implementation
- Enhanced AI Assistance for Developer Onboarding and Support: Integrating Processica’s Tailored Customization
- Comparative Analysis: RAG and P-RAG
- Conclusion and Future Prospects

Three Phases of Augmenting Developer Productivity
At Processica, we are focused on using Generative AI to accelerate and improve various aspects of software development as well as developers’ productivity and well-being.
1. Augment Coding and Testing Activities
GenAI tools are now popular among developers to increase productivity in writing, documenting, and testing code. AI coding assistants can perform various tasks:
Writing code. Develop code snippets and offer recommendations for code completions to cut down on the time spent on writing code and the likelihood of errors.
Documenting code. It will help in automatically generating detailed comments from the code thus making it easier and more efficient.
Testing Code. Create test cases, execute test cases automatically, and report bugs to improve the testing process and free the developers to work on adding more functionality.
2. Enhance Developer Experience
Leading organizations leverage GenAI tools to improve the overall developer experience, addressing constraints in satisfaction, collaboration, and flow:
Satisfaction. Decrease the level of annoyance from repetitive tasks so that developers can focus on other tasks and increase job satisfaction.
Collaboration. Improve collaboration with tools such as code review in real-time and collaborative coding space to enhance the team environment.
Flow. Stay concentrated and efficient by reducing distractions and optimizing the processes by assigning tasks in a smart way and using automated code completion.
3. Maximize Outcome Value
In the final phase, companies should use GenAI tools to maximize the value of outcomes through experimentation and iterative improvement:
Experimentation. Accommodate prototyping and experimenting with several solutions to ensure that the best solution is arrived at quickly.
Iterative improvement. Aid in the tracking of the application usage and gain knowledge on areas that require improvements to meet the ever-changing needs of the users.
Outcome measurement. Identify and monitor important performance metrics that will help to assess the value added and this way to focus on the most effective activities for the organization’s success.
In this way, the three phases described above can help software engineering leaders get the most out of GenAI tools to increase developer productivity and gain valuable results.
Onboarding and Support with AI - Enhancing Developer Integration and Efficiency
In software development, onboarding and continuously supporting new team members is a major challenge. This goes beyond familiarizing them with the company culture to integrating them into the unique programming methodologies, conventions, and codebases of each project. Senior developers and team leads often face repetitive questions, directing newcomers to documentation, and explaining project-specific code, which is time-consuming and detracts from core development tasks.
Imagine a new developer encountering an unfamiliar error or unsure where certain functionalities are within the codebase. They typically seek guidance from a senior developer or team lead, which, while supportive, disrupts the senior developer’s workflow, leading to decreased productivity and extended project timelines.
The issue lies in the repetitive nature of these queries and the lack of a streamlined process for knowledge transfer. Existing documentation may not always provide immediate or nuanced answers, causing further delays and frustration.
To address these challenges, we propose an innovative solution that leverages advanced AI technologies – specifically, Retriever-Augmented Generation (RAG) for Language Models (LLMs) – to develop an intelligent helping system. This system aims to provide real-time, context-aware assistance to developers, effectively reducing the time seniors need to spend on repetitive queries and allowing for a smoother and more efficient onboarding process.
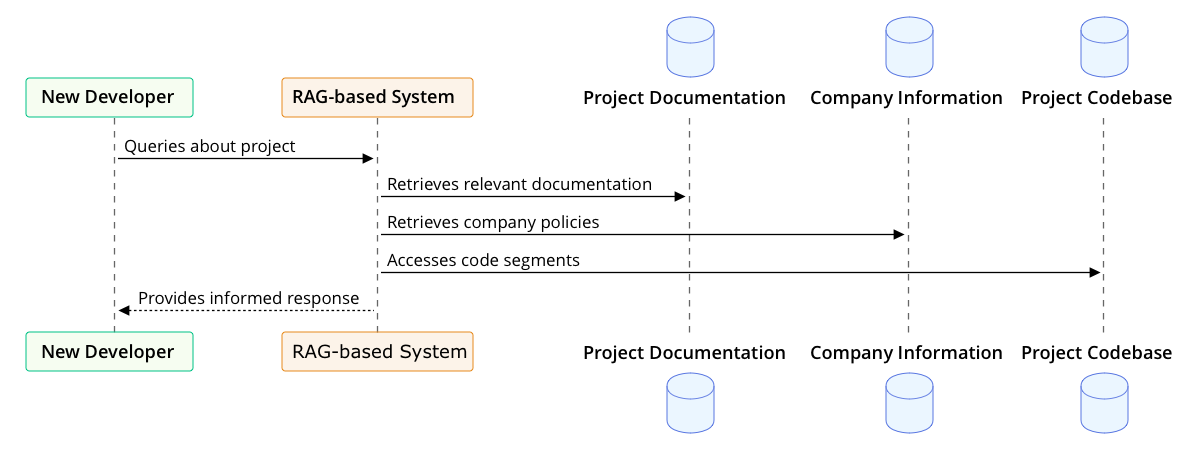
This diagram illustrates the proposed flow of interaction between new developers, the AI assistant, and senior developers. The core idea is to create a system where initial queries are directed towards the AI assistant, which is constantly learning and adapting based on feedback and updates from the senior developers. This not only streamlines the query resolution process but also progressively enriches the AI’s knowledge base, reducing the frequency of direct interventions required from senior staff.
In the following sections, we will delve into the mechanics of the RAG for LLMs, outline our proposed enhancements to this framework, and provide empirical evidence to demonstrate the efficacy of our approach.
Detailing RAG for Language Model Integration in Development Support Systems
Overview of RAG for LLMs
Retrieval-Augmented Generation (RAG) offers a powerful method for enhancing the capabilities of Large Language Models (LLMs) by integrating external knowledge sources directly into the generation process. At the core, RAG combines the retrieval of informational documents and the generative capabilities of LLMs to produce contextually rich and informed responses. This technique significantly enhances the quality of generated text, making it particularly valuable in applications requiring a deep understanding of complex datasets, such as software development environments.
How RAG Works
The RAG framework operates in two main stages:
- Document retrieval. First, given a query or prompt (e.g., a developer’s question about a code module), the system retrieves a set of relevant documents. This retrieval is usually powered by a vector-based search engine which matches the query against a pre-indexed corpus of documents based on semantic similarity.
- Response generation. The retrieved documents are then passed along with the query to the LLM. The model considers both the input query and the content of the retrieved documents to generate a coherent and contextually informed response.
Integration of RAG in Our Development Support System
In our system at Processica, the knowledge base used by the RAG model is meticulously constructed from a variety of rich data sources that are crucial for software development:
- Project documentation. Detailed records of project requirements, specifications, and implementation guidelines.
- Corporate information. Background information about the company, its coding standards, and operational protocols.
- Project’s codebase. Direct access to the repository containing the actual source code, including inline comments and documentation.
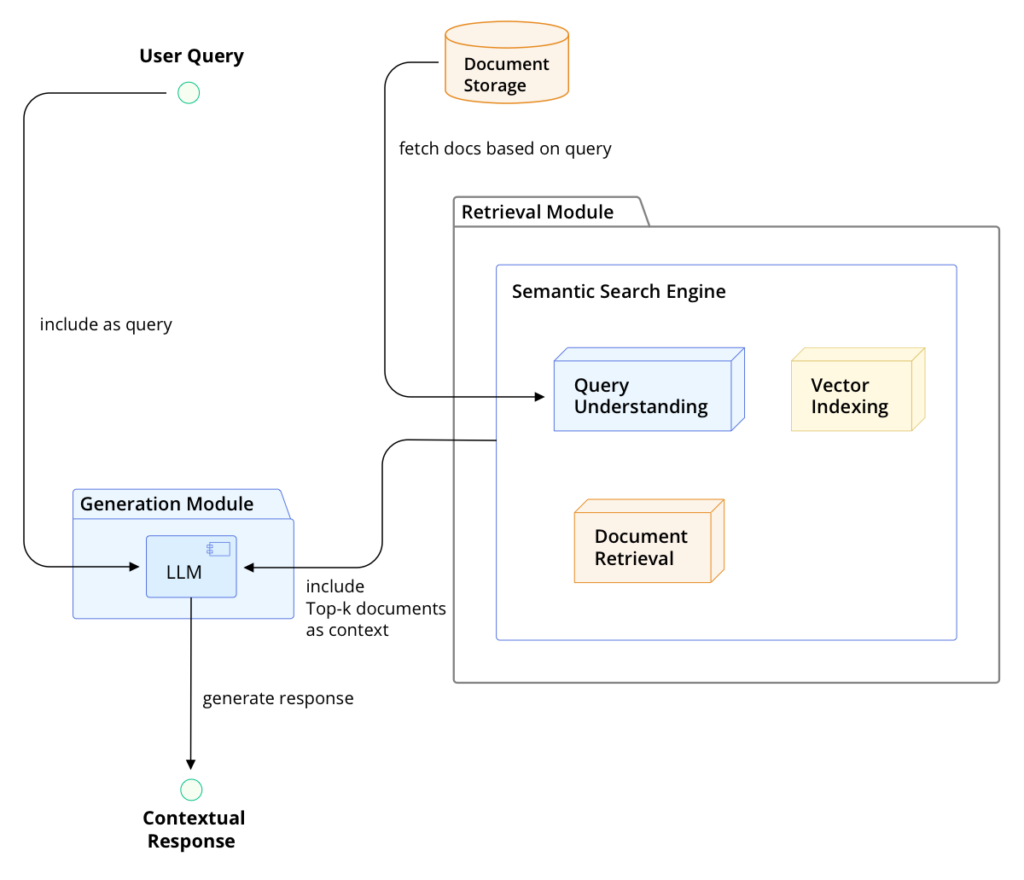
In this setup, each component plays a crucial role. The RAG model first retrieves relevant documents based on the query from the developer. For instance, if a question arises about a specific function in the code, the retrieval system fetches pertinent documents from the project’s documentation and codebase that mention or relate to this function. The selected documents and the original query are then fed into the LLM, which synthesizes the information to generate a precise and informative response.
RAG Implementation
To maximize the efficiency and relevance of document retrieval, which is foundational to the efficacy of the RAG model, we employ sophisticated storage and retrieval systems specifically tailored for handling large datasets typically found in software development environments.
Storage Systems
Elasticsearch. We use Elasticsearch for indexing and storing the project documentation and corporate information. Elasticsearch excels in handling large volumes of text data and offers powerful full-text search capabilities that are crucial for retrieving the most relevant documents quickly and efficiently.
Code Excerpt – Indexing Documents in Elasticsearch:
from elasticsearch import Elasticsearch
# Connect to the local Elasticsearch server
es = Elasticsearch(HOST=”http://localhost”, PORT=9200)
# Index a document
doc1 = {
“document_type”: “project_documentation”,
“content”: “Detailed explanation of module XYZ and its functionalities.”
}
res = es.index(index=”project_docs”, id=1, body=doc1)
print(res[‘result’])
MongoDB. For storing the actual source code and its metadata, MongoDB is used due to its flexibility with schema and high performance with large volumes of unstructured data.
Code Excerpt – Storing Source Code in MongoDB:
from pymongo import MongoClient
# Connect to the local MongoDB database
client = MongoClient(‘localhost’, 27017)
db = client[‘codebase’]
# Insert a code module document
code_module = {
“name”: “ModuleXYZ”,
“code”: “def xyz_function(param): return param * 2”,
“documentation”: “This function doubles the input parameter.”
}
result = db.modules.insert_one(code_module)
print(‘Inserted ID:’, result.inserted_id)
Retrieval System
The retrieval system is designed to work seamlessly with these databases to pull the most relevant documents based on semantic similarity to the query. For this purpose, we integrate a machine-learning model that transforms both the queries and the documents into high-dimensional vectors.
Code Excerpt – Semantic Search with Elasticsearch:
from elasticsearch import Elasticsearch
def search(query, index=”project_docs”):
es = Elasticsearch()
res = es.search(
index=index,
body={“query”: {“match”: {“content”: query}}}
)
return res[‘hits’][‘hits’]
# Example usage
query = “How does the xyz_function work?”
results = search(query)
for doc in results:
print(doc[“_source”])
Combining Technologies for Enhanced Efficiency
By combining Elasticsearch and MongoDB, we ensure that our RAG-based system leverages the strengths of both platforms: Elasticsearch’s powerful text search capabilities and MongoDB’s flexible handling of diverse data types. As documents and code snippets are retrieved, they are passed into the RAG model where they aid in generating precise answers to developer queries. This integration not only improves the response quality but also significantly cuts down on the time developers spend searching for information.
Ensuring these systems work harmoniously involves regular updating and maintenance of indices and data schemas to keep up with the evolving project requirements and corporate standards. The ability to quickly adapt and update the knowledge base is crucial for maintaining a responsive and helpful development support system.
By incorporating RAG, our system not only provides immediate access to essential information but also significantly reduces the time required for developers, especially newcomers, to familiarize themselves with complex project environments. This methodology allows the LLM to act as a knowledgeable assistant who can understand the context and provide responses that are both accurate and directly applicable to the ongoing tasks.
Enhanced AI Assistance for Developer Onboarding and Support: Integrating Processica’s Tailored Customization
Our new system, named Processica Customized Directive System (PCDS), begins with an analysis of user input. Here’s an in-depth look at how we’ve augmented the RAG workflow to create PCDS:
- Tailored customization level. As the initial step, PCDS examines incoming queries from users. It utilizes an advanced algorithm to interpret these queries and align them with senior or lead developers’ guidelines on how to appropriately respond.
- Collection of directives. A crucial component of PCDS is the directive database, populated through an interactive process called ‘God Mode.’ In this mode, leaders actively participate by reading user support interactions and providing corrective explanations. These instructions are used to pair user intents with corresponding directives, which are then stored in a specialized directive database.
- Directive application and response generation. Once a directive is matched to an incoming query, it is fed along with the query into our enhanced language model. This tailored query then undergoes processing through the RAG framework, ensuring that the response is not only accurate but also aligned with project-specific guidelines.
Integration with RAG
Here’s the updated system diagram showing how PCDS integrates within the general RAG workflow:
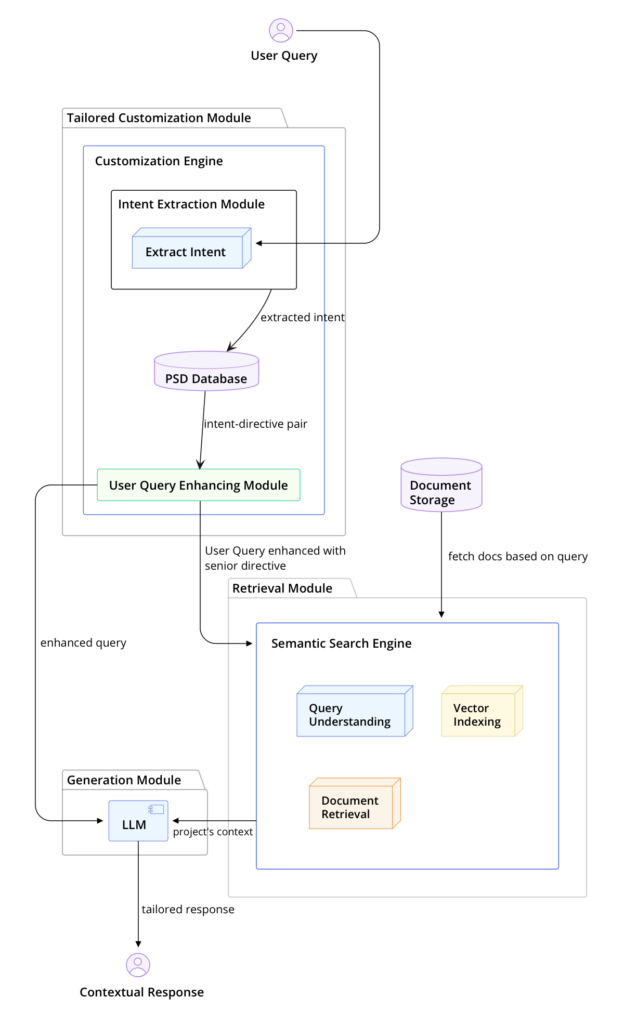
Processica Customized Directive System seamlessly ties into the RAG architecture, creating a far more efficient system tailored for software development environments.
Comparative Analysis: RAG and P-RAG
In this section, we will discuss how the developed RAG system enhanced with Processica Customized Directive System (Precision RAG or P-RAG from now on) excels beyond the traditional RAG approach in streamlining software development onboarding and ongoing support processes. Let’s review key performance metrics, derived from our internal implementations and simulations, to underscore the efficiency and effectiveness of the P-RAG system.
Traditional RAG vs. Precision RAG
The Retrieval-Augmented Generation system forms a baseline in utilizing a large language model with an external knowledge base including project documentation, company information, and codebases. This allows the chatbot to fetch pertinent information and generate responses that are context-aware and technically accurate.
However, our enhanced system takes this a step further by incorporating a tailorable engagement model that actively learns from team leads’ interactions (God Mode Directive Learning). This nuance ensures that the system not only retrieves relevant information but also adapts the communication style and technical depth based on the user’s role and the query context.
For a quantifiable perspective, consider the following key performance indicators from our pilot deployment:
- Consultation time reduction. Under traditional RAG, average developer consultation sessions lasted about 35 minutes. With P-RAG, we’ve reduced the duration to 15 minutes, marking a reduction of nearly 57%.
- Drop in consultation calls. Initially, we recorded an average of 30 weekly consultation calls for new team members. After the integration of P-RAG, this figure dropped to 12, illustrating a 60% decrease.
- Error rate in task execution. Prior to P-RAG, the misinterpretation rate due to unclear or insufficient responses from the bot stood at 20%. Post-implementation, this rate was trimmed down to just 5%.
- Learning curve. New developers typically reached proficiency with the system and codebase within a week using traditional RAG. P-RAG has shortened this to 3 days.
The diagram clearly illustrates the additional layers of cognitive processing and personalized learning enabled by the P-RAG system, which is absent in the traditional model.
Conclusion and Future Prospects
The previous sections have systematically illustrated the inherent advantages of integrating Processica’s P-RAG system within software development environments. As we witnessed, the inaugural implementation within our own teams has not only streamlined the onboarding and support processes but also introduced a higher plateau of efficiency and satisfaction among both new and seasoned developers. Through the strategic use of directive learning and an expansive tailored response system, the P-RAG model has decisively outperformed traditional RAG systems.
Our study highlighted significant metrics affirming the effectiveness of the P-RAG system:
- Reduction in consultation frequency. The number of necessary consultations for new team members experienced a drastic reduction, alleviating the workload on senior developers or team leads.
- Decrease in ramp-up time. The average time required for a new developer to reach operational proficiency was shortened, accelerating the overall project progress.
- Enhancement in developer interaction. There was a marked improvement in the quality and relevance of interactions between developers, attributable to the nuanced understanding and application of project-specific conventions and standards.
These enhancements contribute not only to operational efficiency but also elevate the overall cognitive environment, thereby fostering a more dynamic and responsive developmental framework.
Broader Implications
The success of the P-RAG integration hints at its scalable utility in various facets of software development. Given its flexibility and adaptability, this system can be seamlessly introduced into different contexts where software development is pivotal, ranging from small startups to large multinational corporations.
Future Prospects
Looking forward, the P-RAG system holds promising potential for further integration and expansion. A particularly exciting direction is its potential synergy with AI-driven tools like Microsoft’s GitHub Copilot. Below is a conceptual diagram of this integration:
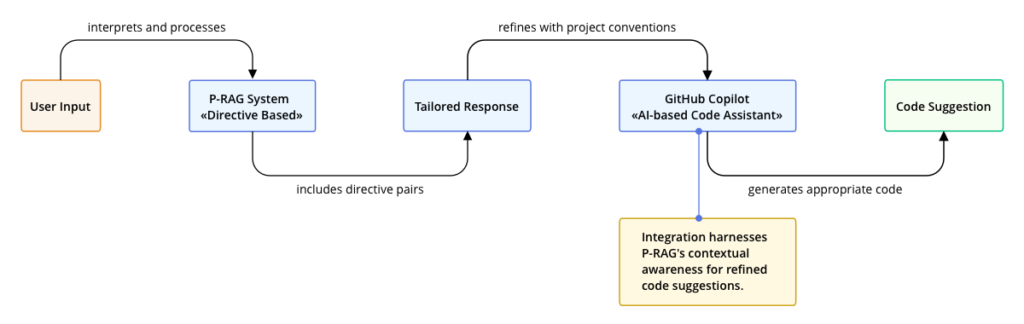
The integration of P-RAG with GitHub Copilot could revolutionize how coding suggestions are generated, ensuring they are not only syntactically correct but also aligned with the specific conventions and requirements of the ongoing project. This capability will drastically enhance the precision of automated code generation, making it more usable and compliant with existing project standards.
In conclusion, the evolution from basic RAG systems to Processica’s P-RAG signifies a substantial leap forward in AI-driven developer support mechanisms. The proposed future integrations not only promise to amplify the utility of this system but also open new horizons for comprehensive, intelligent automation in software development landscapes. As we advance, the potential for such integrative AI systems to fundamentally redefine software development practices is both immense and inspiring.
To stay ahead in this rapidly evolving field and maximize your development team’s productivity and efficiency, partnering with Processica for AI-powered development services is a strategic move. Our expertise in cutting-edge AI technologies and proven track record in delivering innovative solutions can help your organization harness the full potential of AI-driven tools. Contact Processica today to learn how we can transform your software development processes, enhance your team’s performance, and drive your projects to new heights. Let’s collaborate to shape the future of software development together.
